コーススケジュール
目次
BERT の正式名は、Bidirection Encoder Representation from Transformers で、事前トレーニングされた言語表現モデルです。これは、従来の一方向言語モデルや、事前トレーニング用に 2 つの一方向言語モデルを浅く結合する方法ではなく、新しいmasked language model (MLM) であることを強調しています。深い双方向言語表現。BERT の論文が発表されたとき、新しい state-of-the-art の結果が 11 個の NLP (Natural Language Processing、自然言語処理) タスクで得られたと述べられました。落ちる。
このモデルには次の主な利点があります。
1) MLM を使用して双方向 Transformers を事前トレーニングし、深い双方向言語表現を生成します。
2) 事前トレーニング後は、fine-tune の出力レイヤーを追加するだけで、さまざまなダウンストリーム タスクで state-of-the-art のパフォーマンスを達成できます。このプロセスでは、BERT に対するタスク固有の構造変更は必要ありません。
では、BERT はどのようにしてそれを達成したのでしょうか?
1. BERTの構造
以前の事前トレーニング モデルの構造は、一方向言語モデル(左から右または右から左)によって制限され、モデルの表現能力も制限されるため、コンテキスト情報のみを取得できます。ひとつの方向。そして、BERT は事前トレーニングに MLM を使用し、深い双方向の Transformer コンポーネントを使用します(一方向の Transformer は一般に Transformer decoder と呼ばれ、各 トークン (シンボル) は現在の左 にのみ attend します。双方向の Transformer は Transformer encoder と呼ばれ、その token のそれぞれがすべての token に attend してモデル全体を構築するため、最終的には左と右を融合できる深い双方向言語表現を生成します。コンテキスト情報。Transformer の詳細な説明については、tention Is All You NeedまたはThe Illustrated Transformer (推奨!)を参照してください。
Transformer の詳細な構造が隠されている場合は、入力と出力のみを備えたブラック ボックスで表現できます。
 ブラックボックス変圧器
ブラックボックス変圧器
そして、Transformer 構造をスタックして、より深いニューラル ネットワークを形成できます (ここでは、Transformer encoder をスタックすることも理解できます)。
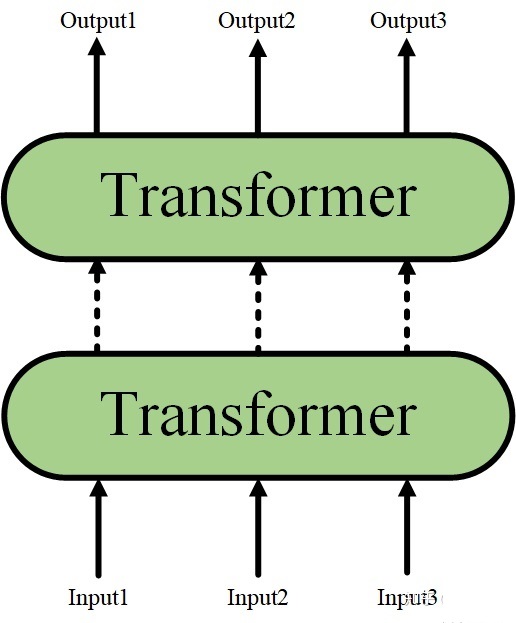 Transformer 構造をスタックする
Transformer 構造をスタックする
最後に、多層の Transformer 構造を積層した後、BERT の主要な構造が形成されます。
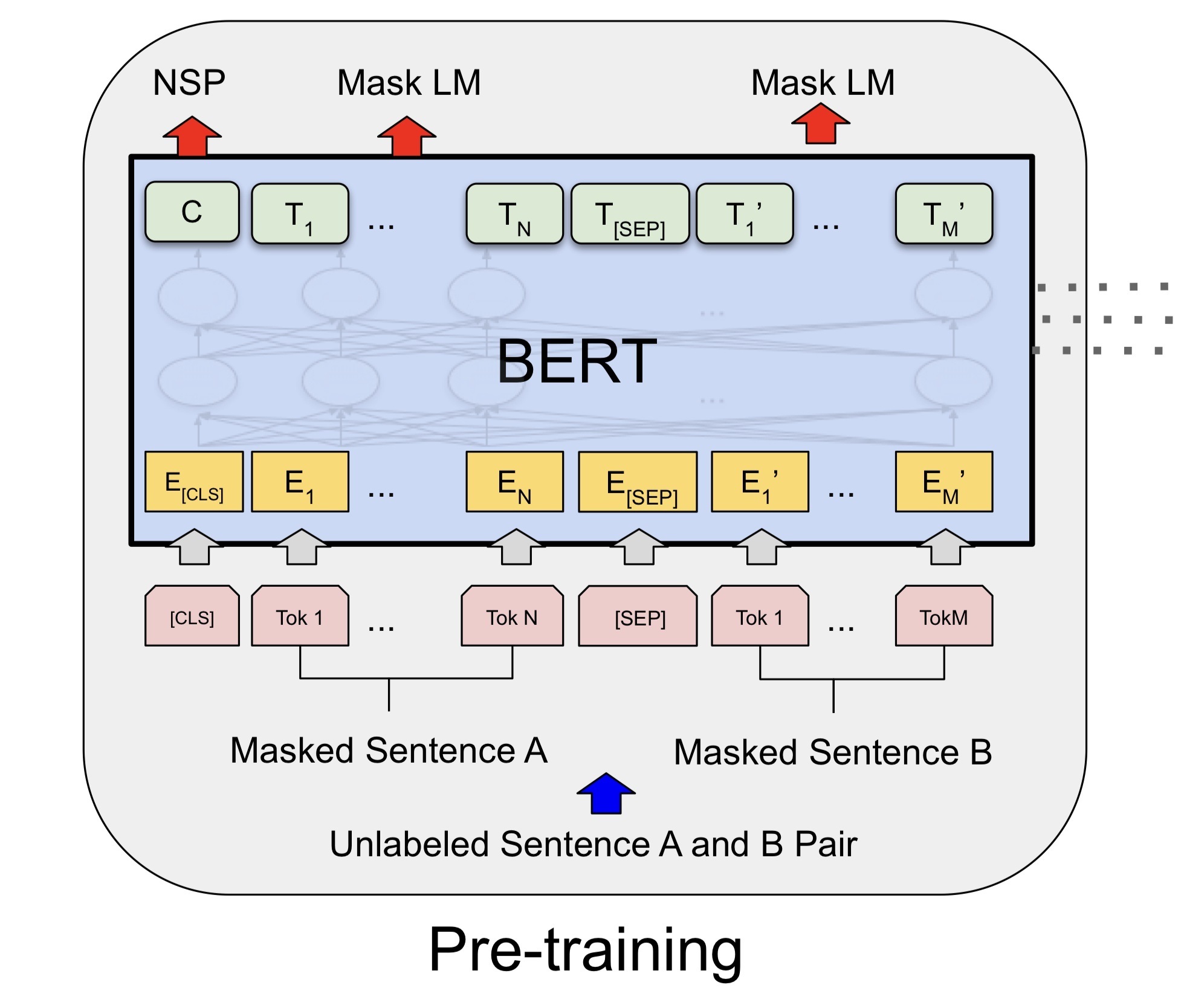 BERTの主な構造
BERTの主な構造 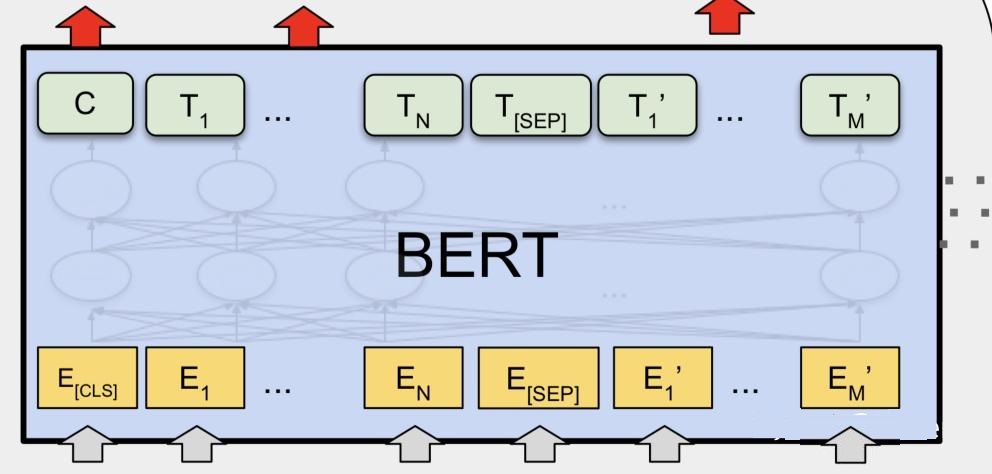 この部品は複数のトランス構造によって積み重ねられています。
この部品は複数のトランス構造によって積み重ねられています。
ダウンストリームタスクが異なると、BERT の構造に若干の変更が生じる可能性があるため、次にトレーニング前段階のモデル構造のみを紹介します。
1.1 BERTの入力
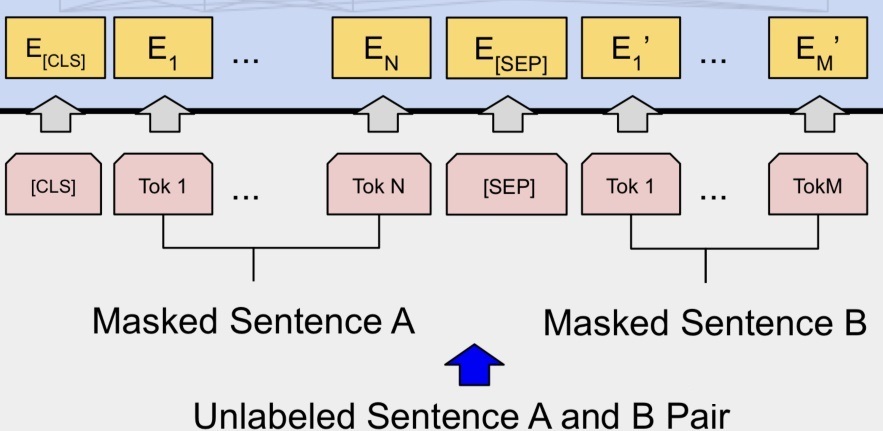 BERTへの入力
BERTへの入力
BERT の入力は、各 token に対応する表現(図のピンクのブロックが token、黄色のブロックが token に対応する表現) であり、 WordPiece アルゴリズムを使用して単語辞書が構築されます。特定の分類タスクを完了するために、単語の token に加えて、作成者は各入力シーケンスの先頭に特定の分類 token ([CLS])を挿入し、それに対応する最後の Transformer レイヤー出力も挿入します。分類に token シーケンス全体の表現情報を収集するために使用されます。
BERT は事前トレーニングされたモデルであるため、さまざまな自然言語タスクに適応する必要があります。そのため、モデルによるシーケンス入力には 1 つの文(テキスト感情分類、シーケンスのラベル付けタスク)または 3 つ以上の文を含めることができる必要があります(テキストの要約、自然言語推論、質問応答タスクなど)。では、どの範囲が文 A に属し、どの範囲が文 B に属するかを区別できるモデルを作成するにはどうすればよいでしょうか。BERT はこれを解決するために 2 つの方法を採用しました。
1)シーケンス token 内の各文の後に分割 token ([SEP])を挿入して、異なる文 token を分離します。
2) 各 token 表現に学習可能なセグメンテーション embedding を追加して、文 A に属するか文 B に属するかを示します。
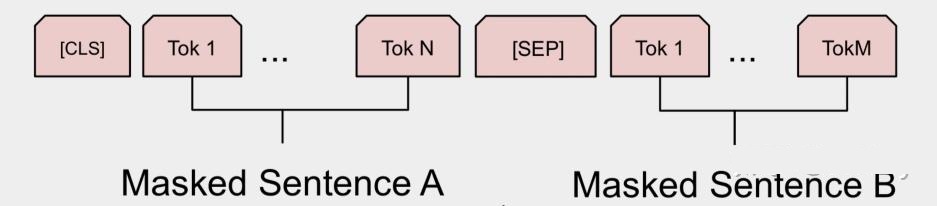
したがって、最終モデルの入力シーケンス token は次のようになります(入力シーケンスに 1 つの文しか含まれていない場合、[SEP] 以降の token は存在しません)。
 モデルの入力シーケンス
モデルの入力シーケンス
BERT の入力が各 token に対応する表現であることは上で述べましたが、実際、この表現は対応する token 、セグメンテーション、位置embeddingsの3つの部分で構成されます(位置 embeddings の詳細な説明については、以下に示すように、Attend Is All You Need または The Illustrated Transformer) を参照してください。
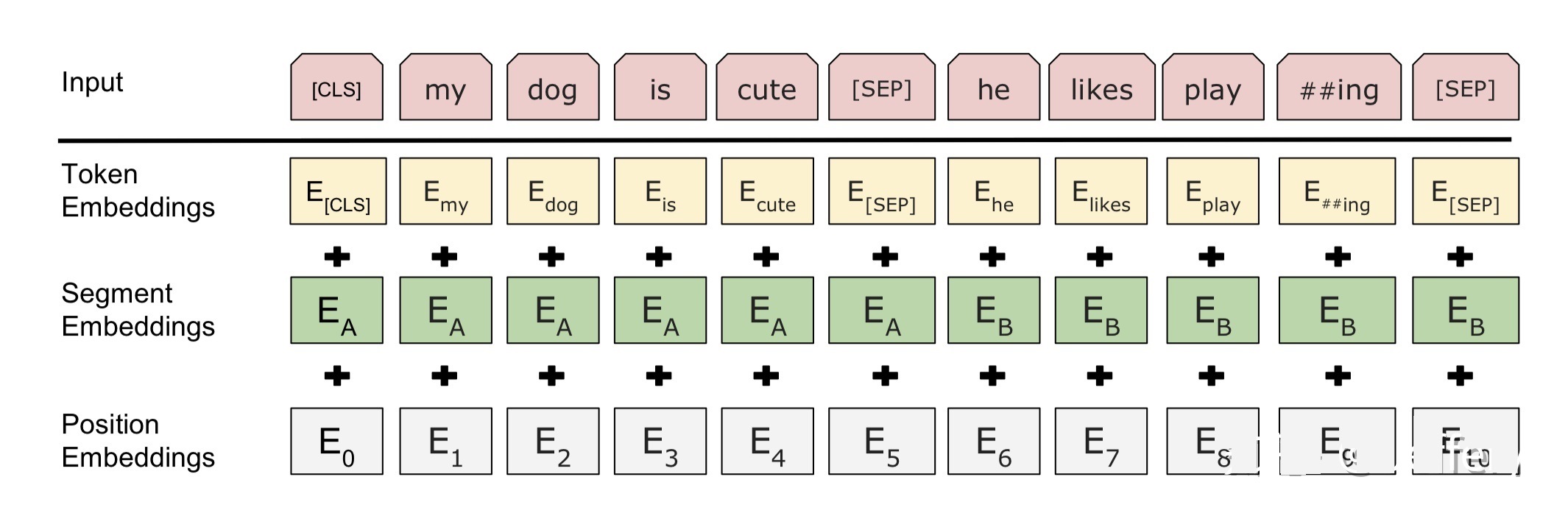 トークン表現の構成
トークン表現の構成
ここまで BERT の入力を紹介しましたが、その設計思想は非常にシンプルかつ効果的であることがわかります。
1.2 BERTの出力
BERT の入力を導入すると、BERT の出力を実際に出力する準備が整います。これは、Transformer の特性として、次の図に示すように、入力と同じ数の対応する出力があるためです。
 BERT の出力
BERT の出力
Cは最後の Transformer の出力に対応するカテゴリ token ([CLS]) であり、T_iは最後の Transformer の出力に対応する他の token を表します。一部の トークン レベルのタスク(シーケンスのラベル付けや質問応答タスクなど)では、予測のために追加の出力層にT_iを入力します。一部の文レベルのタスク(自然言語推論や感情分類タスクなど)では、C が追加の出力層に入力されます。これは、各 token シーケンス token の前に特定の分類が挿入される理由を説明します。
ここまでは BERT の入力と出力について紹介しましたが、より具体的な詳細は元の論文で確認できます。
2. BERT 事前トレーニング タスク
実際、事前トレーニングの概念は CV (Computer Vision、コンピューター ビジョン) ではすでに非常に成熟しており、広く使用されています。CV で使用される事前トレーニング タスクは一般に ImageNet 画像分類タスクです。画像分類タスクを完了するための前提条件は、優れた画像特徴を抽出できることです。同時に、ImageNet データセットには大規模な利点があります。規模が大きく、品質も高いため、多くの場合、優れた結果が得られます。
NLP フィールドには、ImageNet のような人間による注釈が付けられた高品質のデータはありませんが、大規模なテキスト データの自己教師ありの性質を利用して、事前トレーニング タスクを構築できます。そこで BERT は、 Masked Language ModelとNext Sentence Predictionという 2 つの事前トレーニング タスクを構築しました。
2.1 マスクされた言語モデル (MLM)
MLM は、BERT が一方向言語モデルによって制限されない理由です。簡単に言うと、mask token ([MASK]) を使用して、各トレーニング シーケンス内の token を 15% の確率でランダムに置き換え、[MASK] の位置で元の単語を予測します。ただし、[MASK] はダウンストリーム タスクの微調整 (fine-tuning) ステージには現れないため、事前トレーニング ステージと微調整ステージの間に不一致が生じます (ここでよく説明されています)。つまり、事前トレーニングターゲットは、結果の言語表現を [MASK] には敏感ですが、他の トークンには鈍感にします)。したがって、BERT はこの問題を解決するために次の戦略を採用します。
まず、各トレーニング シーケンスにおいて、特定の token 位置が 15% の確率で予測用にランダムに選択され、i 番目の token が選択されると、次の 3 つの token のいずれかに置き換えられます。
1) 80% の確率で [MASK]。たとえば、私の 犬 は毛深い—>私の犬 は[MASK]
2) 10% の確率で、他の token がランダムになります。たとえば、私の 犬 は毛深い—>私の犬 はapple
3) 10% の確率で、それは元の token です(変更されないままですが、個人的には 2 に対応する否定クラスだと思います)。たとえば、私の 犬 は毛深い—>私の犬 は毛深い
次に、この位置に対応するT_iを使用して元の token を予測します (完全な接続に入力し、softmax を使用して各 token の確率を出力し、最後にクロスエントロピーを使用して loss を計算します)。
この戦略により、BERT は [MASK] だけでなく、すべての トークンに対して敏感になり、トークンの表現情報を抽出できるようになります。論文内のこの戦略に関する実験データは次のとおりです。
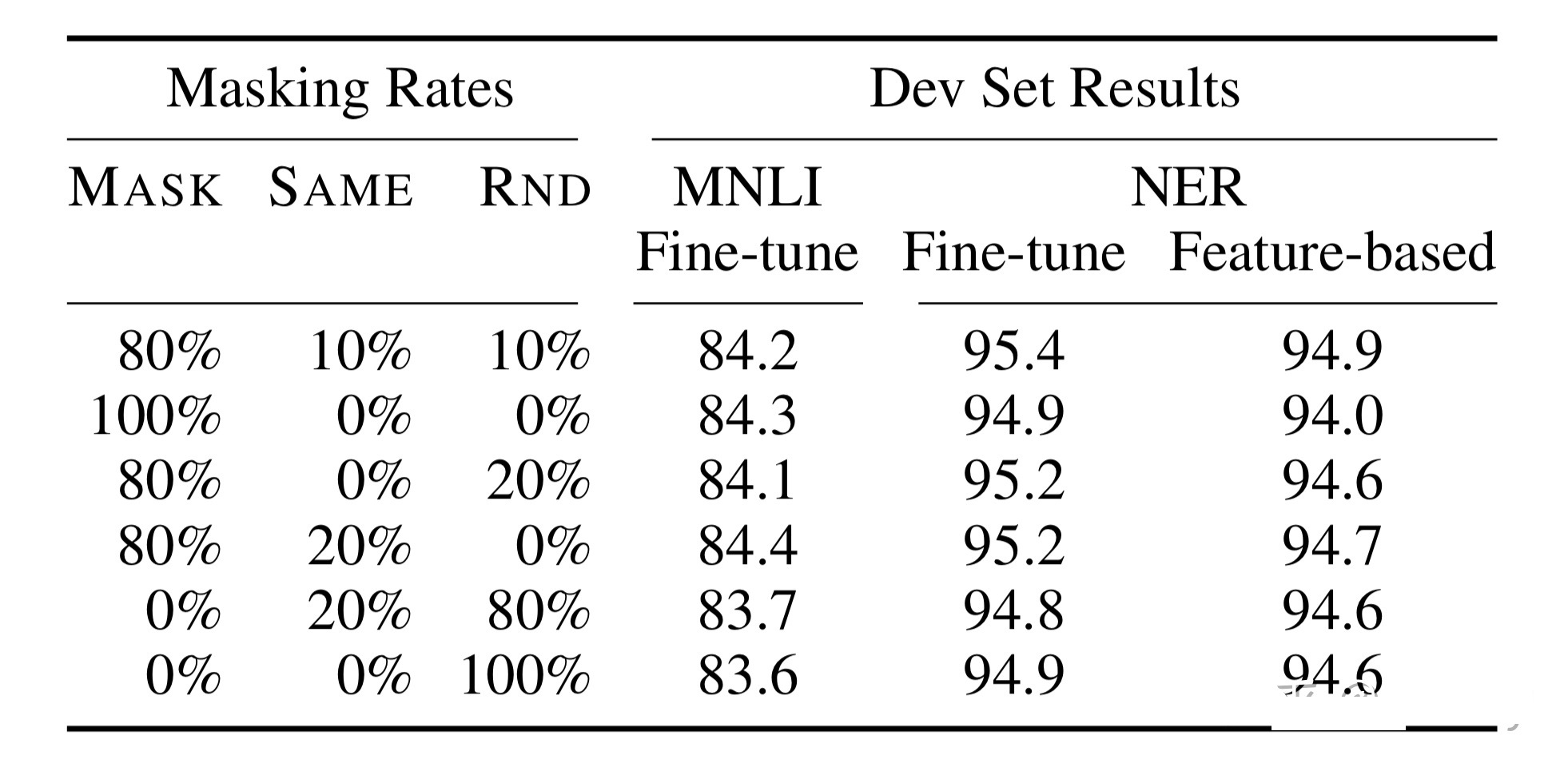 さまざまな戦略の実験結果
さまざまな戦略の実験結果
2.2 次の文の予測 (NSP)
質問応答や自然言語推論などの一部のタスクでは 2 つの文間の関係を理解する必要がありますが、MLM タスクはトークン レベルの表現を抽出する傾向があるため、文レベルの表現を直接取得することはできません。モデルが文間の関係を理解できるようにするために、BERT は事前トレーニングに NSP タスクを使用します。簡単に言えば、2 つの文が互いに接続されているかどうかを予測します。具体的な方法は次のとおりです。トレーニング例ごとに、コーパス内の文 A と文 B を選択して形成します。50% の確率で文 B が文 A の次の文 (IsNext としてマーク) となり、次の 50% の確率で、文 B はコーパス内のランダムな文になります(NotNext アノテーションが付けられています)。次に、トレーニング サンプルを BERT モデルに入力し、[CLS] に対応する C 情報を使用して 2 つの分類を予測します。
2.3 トレーニング前のタスクの概要
最終的なトレーニングの例は次のようになります。
Input1=[CLS] その男 行った to [MASK] store [SEP] 彼 買った a ガロン [MASK] milk [SEP]
Label1 = IsNext
Input2=[CLS] the man [MASK] to store [SEP] ペンギン [MASK] are flight ##less birds [SEP]
Label2 = NotNext
各トレーニング サンプルを BERT に入力して 2 つのタスクに対応する loss を取得し、これら 2 つの loss を加算して全体的なトレーニング前の loss を形成します。(つまり、2 つのタスクが同時にトレーニングされます)
これら 2 つのタスクに必要なデータは、実際にはラベルなしのテキスト データ (自己教師ありの性質) から構築できることがはっきりとわかります。これは、CV で手動のアノテーションを必要とする ImageNet データセットよりもはるかに単純です。