コーススケジュール
目次
- オープンソース Stable Diffusion
- Stable Diffusion テキスト生成画像処理
- Stable Diffusion の改善 1: 画像圧縮
- Stable Diffusionの改善2:逆拡散処理
- Stable Diffusion の完全な構造
- Midjourney
- 要約する
次に、Stable Diffusion がテキストに基づいて画像を生成する仕組みと、Diffusion と比較してどのような最適化が行われているかを紹介します。
上部に次のように書きます。
Stable Diffusion での拡散処理の記述は、記述方法のバージョンが多く、例えばフォワード処理はノイズ付加処理とも言えますが、ここでは理解を容易にするために様々な記述を説明します。 。
- 拡散拡散モデル: 記事内で拡散拡散モデルが登場する箇所はすべて DDPM モデルを参照しています。 DDPM: 2020 年に提案されたノイズ除去拡散確率モデル
- 順拡散処理、ノイズ付加処理(同義、以下同じ)
- 逆拡散処理、ノイズ除去処理、画像生成処理、サンプリング
- シングルラウンドのノイズ除去プロセス、シングルラウンドの U-Net プロセス、シングルラウンドの逆拡散プロセス
オープンソース Stable Diffusion
現在、最も人気のある AI ペイントは Midjorney と Stable Diffusion ですが、Midjourney はオープンソースではないため、主に Stable Diffusion を共有し、Midjourney については後ほど紹介します。
公開情報によると、Stable Diffusion は2022 年に StabilityAI によって提案され、論文とコードの両方がオープンソース化されました。StabilityAI は 10 月 28 日に 1 億 100 万ドルの資金調達を完了し、現在の評価額は 10 億ドルを超えています。
ウェブサイト Stable Diffusion Online にアクセスして Stable Diffusion を体験できます。「'A sunset over a mountain range, vector image」(山の夕日)というテキストを入力します。見てみましょう 効果:
アプリケーションを理解したら、Stable Diffusion を導入しましょう。重要なことは、手間がかかると思われる多くの式の導出を避けるために図を使用することです。
1. Stable Diffusion テキスト生成画像処理
Stable Diffusion は実際には Diffusion の改良版であり、主に Diffusion の速度の問題を解決します。では、Stable Diffusion はどのようにしてテキストに基づいた画像を思いついたのでしょうか? 次の図は、Stable Difffusion が画像を生成する具体的なプロセスを示しています。
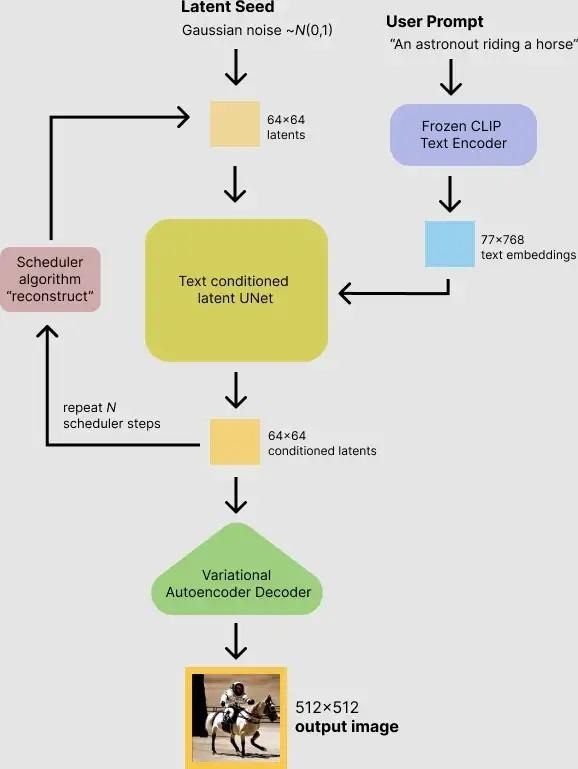
入力テキスト (図の「An astronout riding a horse」) が CLIP モデルを通じて text embedding に変換され、初期画像 (ランダムを使用して初期化) と比較されることがわかります。ガウス ノイズ Gaussian Noise) はノイズ除去モジュールを一緒に入力し (つまり、ピクチャ内の Text conditioned latent U-Net)、最終的にサイズ512\times512のピクチャを出力します。記事 (Top Secret Ambush: Ten Minutes to Understand Diffusion: Graphical Diffusion Diffusion Model) では、CLIP モデルと U-Net モデルの一般原理をすでに理解しています。ここで重要なのは Text conditioned latent U-net、翻訳はテキスト条件付きの隠れた U-net ネットワークです。実際、U-Net にマルチヘッド Attend メカニズムを導入することにより、入力テキストは画像に関連付けられます。この作品が後にどのように機能するかに焦点を当てます。
2. Stable Diffusion の改善 1: 画像圧縮
Stable Diffusion の元の名前は " Latent Diffusion Model " ( LDM ) です。拡散プロセスが潜在空間 (latent space) で行われることは明らかであり、実際には画像圧縮です。 、これは Stable Diffusion が Diffusion よりも速い理由でもあります。
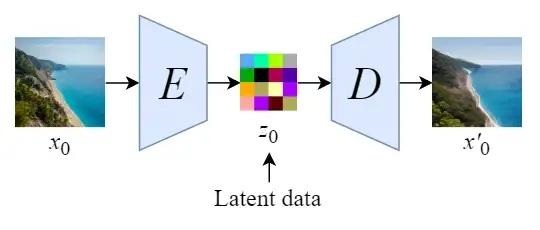
Stable Diffusion は、まずオートエンコーダーをトレーニングして、画像を低次元表現に圧縮する方法を学習します。
- トレーニングされたエンコーダEを通じて、オリジナル サイズの画像を低次元の潜在データに圧縮できます (画像圧縮)
- トレーニングされたデコーダDを通じて、潜在データを画像の元のサイズに復元できます。
画像を latent data に圧縮した後、拡散プロセスは latent space で完了できます。次の図に示すように、Diffusion 拡散プロセスとの違いを比較してください。
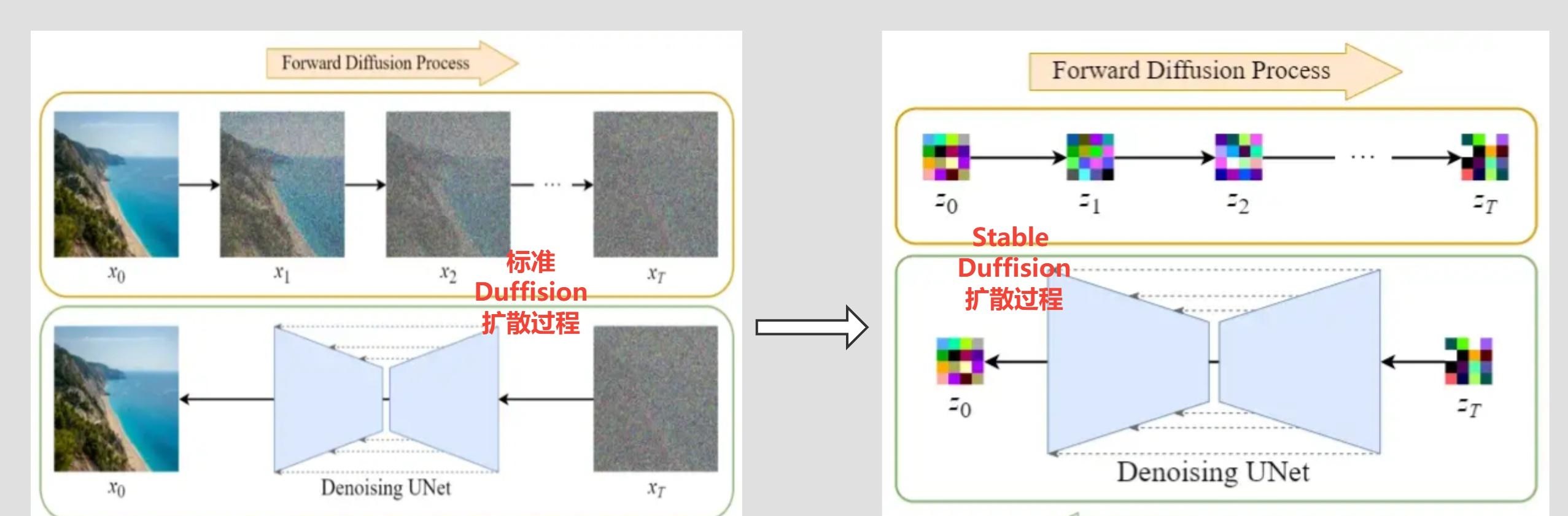
Diffusion 拡散モデルは元のイメージxに対して操作され、Stale Diffusion は圧縮イメージzに対して操作されることがわかります。
Stable Diffusion の順拡散プロセスは、追加の画像圧縮があることを除いて、基本的に Diffusion 拡散モデルと同じですが、逆拡散プロセスの前に 2 つの間には依然として違いがあります。
3. Stable Diffusionの改善2:逆拡散処理
最初のセクションでは、Stable Diffusion テキストから画像を生成するプロセスを簡単に紹介しましたが、ここでは次の図に示すように、詳細を展開して見ていきます。
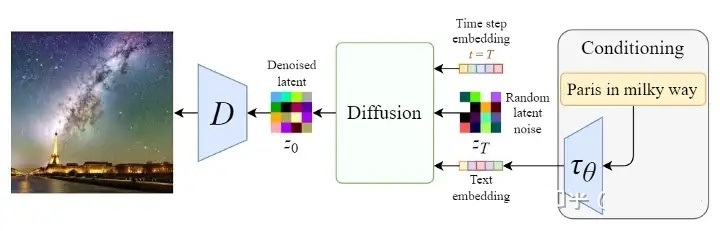
上の図は右から左に、入力テキストは「Pairs in milky way」(天の川のパリ)で、 CLIP モデル\tau_{\theta}を通じて Text embedding に変換され、次に、初期画像 (ノイズ ベクトルz_T )、 Time step ベクトルT を使用して Diffusion モジュールを一緒に入力し (複数回のノイズ除去プロセス)、最後に出力画像z_0をデコーダーDに渡します。最終的なイメージを生成します。
Stable Diffusion は実際には逆拡散プロセスの改良ではなく、テキストの入力をサポートするだけであり、ノイズ除去の各ラウンドでテキストと画像が関連付けられるように U-Net の構造が変更されました。前回の記事 (極秘の待ち伏せ: Diffusion を理解するための 10 分: Diffusion 拡散モデルの図) で、Diffusion 拡散モデルを使用して画像を生成することを紹介したときに、拡散プロセス中にテキスト入力をサポートする方法をすでに紹介しました。 . 、U-Net の構造を変更する方法について説明しています。U-Net 構造の改善について大まかに紹介しただけです。興味のある方は、最初のセクションにアクセスしてください。次に、Stable Diffusion が U-Net の構造を変更して入力テキストをより適切に処理する方法を紹介します。
3.1 逆拡散の詳細: シングルラウンド ノイズ除去 U-Net によるマルチヘッド アテンションの導入 (U-Net 構造の改善)
以下の図に示すように、まず逆拡散の全体的な構造を見てみましょう。
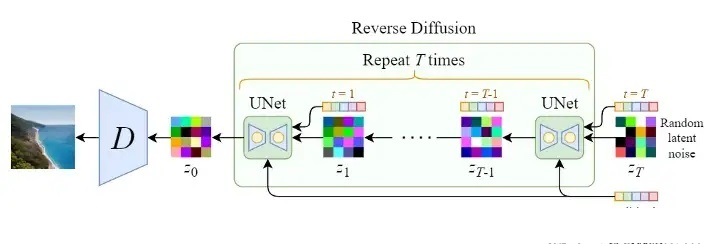
上図から分かるように、逆拡散処理における入力テキストと初期画像Z_Tは、U-Net ネットワークのT ラウンド ( T ラウンドのノイズ除去処理)を経て、最後に最終画像を取得するためにデコードした後、出力Z_0を取得します。テキストベクトルの処理のため、テキストと画像を関連付けることができるようにU-Netネットワークを調整する必要があります。次の図は、単一ラウンドのノイズ除去プロセスを示しています。
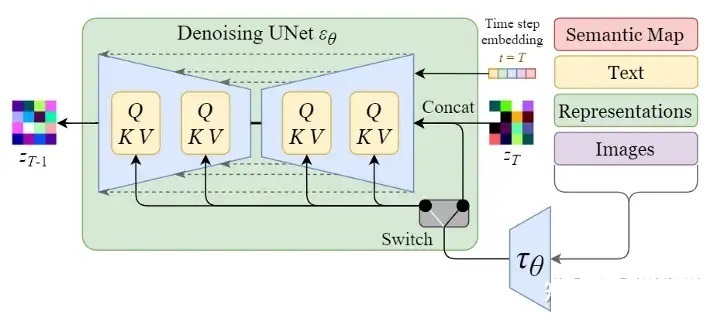
上の図の左端にある Semantic Map、Text、Representations、Images は少し理解しにくいですが、これは、Stable Diffusion がさまざまなタスクを処理するための一般的なフレームワークです。
- セマンティック マップ: セマンティクスを通じて画像を生成するタスクを表します。
- テキスト: テキストから画像を生成するタスクを表します。
- 表現: 言語記述を通じて画像の生成を表現します。
- 画像: 画像に基づいて画像を生成することを意味します
ここでは、入力が Text であることだけを考慮します。そのため、テキスト ベクトルは最初にモデル CLIP モデルを通じて生成され、次に U のマルチヘッド Attend(Q, K, V) に入力されます。 -Netネットワーク。
Stable Diffusion の完全な構造
最後に、以下の図に示すように、テキスト ベクトル表現、初期イメージ (ランダム ガウス ノイズ)、および時間 embedding を含む Stable Diffusion の完全な構造を見てみましょう。
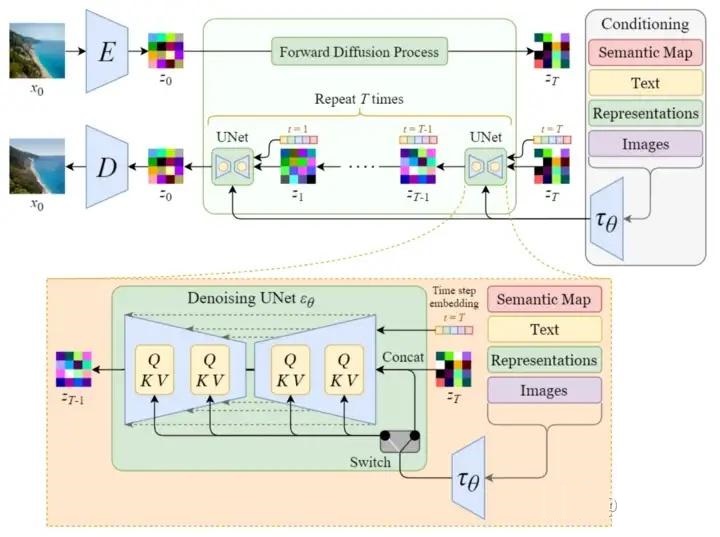
上図はStable Diffusionの順拡散と逆拡散の全体処理を詳細に示したものですが、入力テキストの処理を行わずに任意の画像を生成するだけのDiffusion構造を見てみましょう。
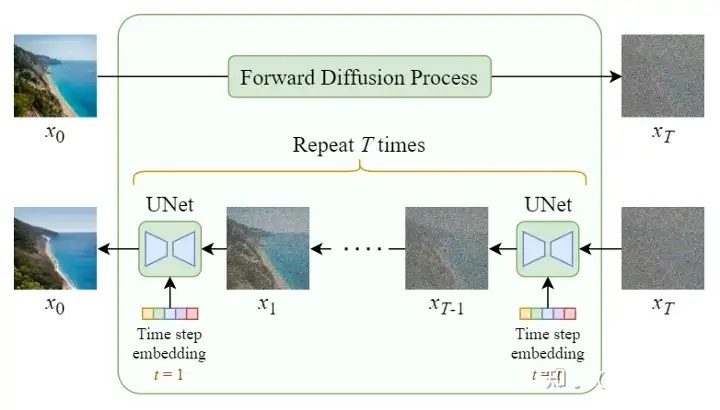
Stable Diffusion と比較すると、テキスト入力を処理せずに任意の画像を生成する Diffusion モデルには 2 つの主な違いがあることがわかります。
- 入力テキストの埋め込み処理の削減 (エンコーダE、デコーダDの削減)
- U-Net ネットワークにはマルチヘッド アテンション構造がありません
Stable Diffusion に加えて、Midjourney も最近非常にサークルから外れています。簡単に紹介しましょう。
Midjourney
Midjourney は、David Holz によって作成された AI 描画ツールです。Midjourney は現在、月収200 万ドルを超えており、Discord プラットフォームの newbie チャンネルを通じて利用できます。Discord プラットフォームは、月間アクティブ ユーザー数が1 億 5,000 万人を超えるゲーム チャット プラットフォームであり、そのうち Midjounery を使用しているユーザー数は380 万人を超えています。2021 年初め、Discord は Microsoft からの 120 億ドルの買収提案を拒否しました。基本的に Discord はコミュニティであり、Midjourney は Discord 上に独自のサーバーを作成し、多数のチャンネルを作成し、独自のボットを開発することでユーザーにサービスを提供します。
ユーザーは Midjourney ホームページから「Join the Beta」をクリックすると、Discord のチャンネルに直接移動します。
上の図は、ユーザー数が 381 万人、現在オンラインのユーザー数が 300,000 人であることを示しています。ユーザーが Midjorney を使用するのも非常に簡単で、ホームページの左下にある newbie チャンネルをクリックして入るだけです。
newbie チャンネルに入ったら、/imagine+プロンプト ワードを使用して Midjourney に画像を生成させることができます
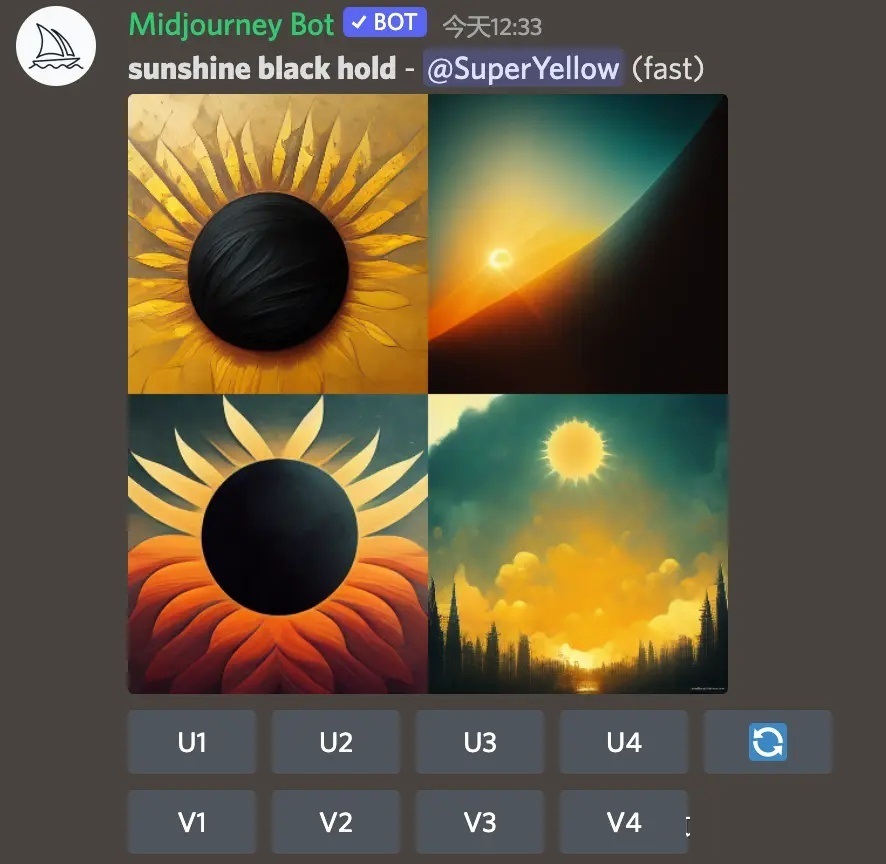
「sunshine black hold」と入力すると4枚の画像が生成されたことがわかります。
Midjourney は現時点ではオープンソースではないため、その背後にあるテクノロジーはわかりませんが、依然として Diffusion 拡散モデルに基づいている可能性が高いです。
要約する
AIGC の爆発により、さまざまなアプリケーションが登場し始めましたが、AIpainting はその典型です。現在最も注目されている AI ペイント モデルは Stable Diffusion ですが、現時点では Stable Diffusion に関する記事はあまり多くなく、主にアプリケーションの紹介に偏っています。入力テキストの処理方法やノイズ除去処理の詳細については、この領域の記事を参照してください。まだ比較的少数ですが、この記事を書く目的は、Stable Diffusion を明確にし、より多くの人に理解してもらうことです。